Jotting
From Gradient Descent to Reinforcement Learning: A Framework for Finding Research Ideas
Let’s begin with a scene every graduate student knows too well. It’s late at night. Your group meeting is tomorrow. You’re staring at a freshly published state-of-the-art (SOTA) paper, and that familiar mixture of admiration and dread has settled in your chest.
The method is clever. But admiring it isn’t really why you’re here. You’re scanning for gaps, for some overlooked corner you can pry open into a follow-up paper. And somewhere in the back of your mind, your advisor’s deceptively mild question from last week is still running on loop: “So, do you have any new ideas lately?” It lands less like curiosity and more like a system alert: Warning: your publication gradient is vanishing.
The word “idea” carries a kind of mythology. We tend to imagine it as a bolt of inspiration, something that arrives through talent, intuition, or sheer luck. This framing reduces research to a lottery: you either draw the winning ticket, or you spend your career waiting for one. It is a miserable way to do science.
So the question worth asking is: is there a more reliable framework? One that transforms “finding an idea” from a random process into something more principled and repeatable?
I’ve read many takes on this problem, and I’ve noticed one perspective that almost never gets mentioned: drawing on the logic of gradient descent and reinforcement learning to guide how we think about research.
Most of you who have taken CS231n will recognize gradient descent immediately. At its core, it is the process of repeatedly stepping downhill on an error surface until you reach the valley of minimum loss. Formally, it is the iterative update
\[x \leftarrow x - \eta \nabla L(x),\]where the local derivative continuously reduces $L$. Given enough iterations, it converges to a local minimum; if $L$ is convex, that point is also globally optimal. This elegantly describes how we solve a problem once it has been clearly defined.
But here lies an inherent limitation. Gradient descent tells you how to move, not where to go. It assumes you already have a map (the loss function) and tasks you with finding the lowest point on it. What if the map itself is wrong? Or what if it captures only a small, irrelevant corner of a much larger world? You could spend your entire career descending with exquisite precision into a valley that was never worth entering in the first place.
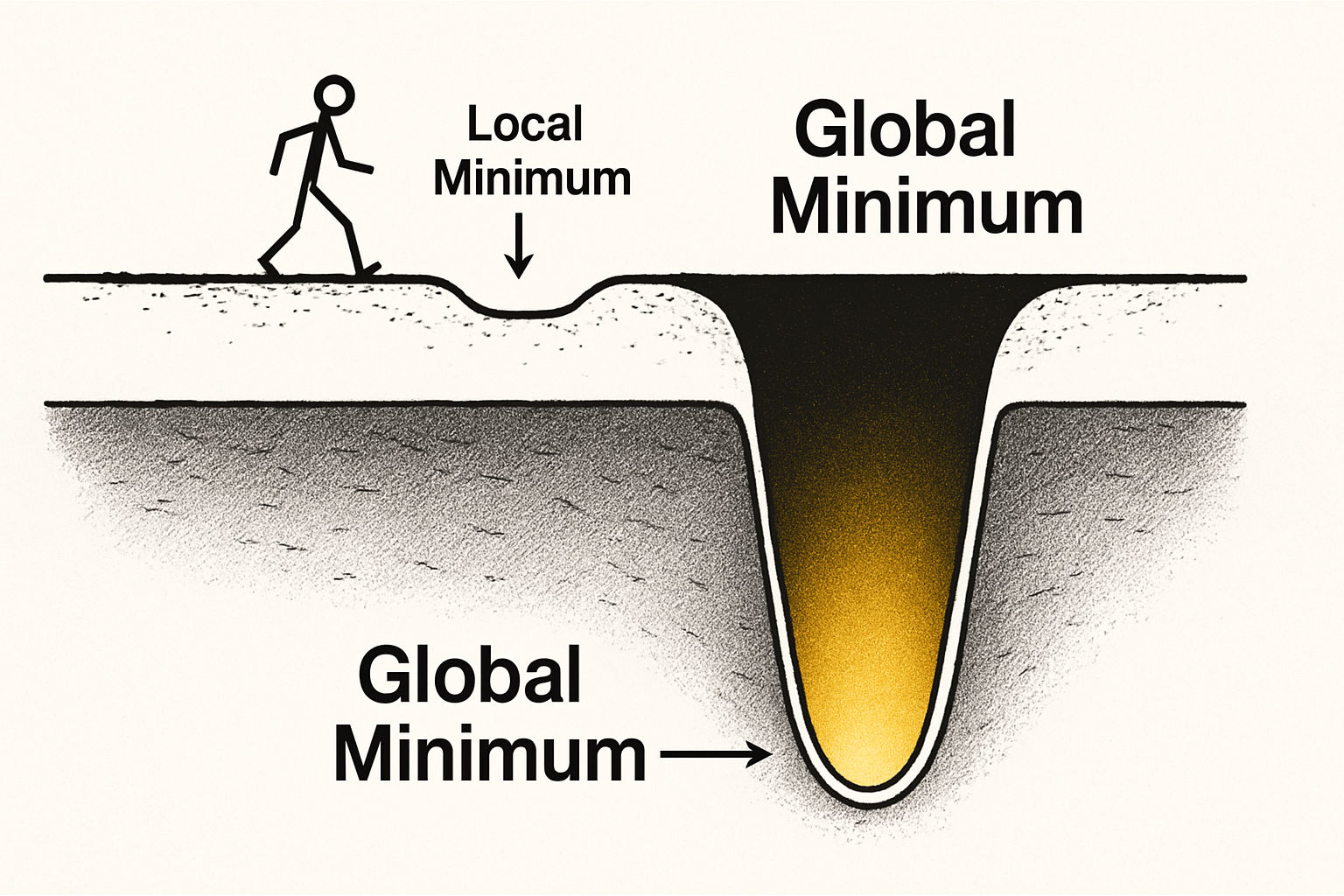
This unease, the suspicion that you might be optimizing your way toward the wrong destination, forces you to lift your eyes from the path and look beyond the lit terrain toward the periphery.
And this is exactly where gradient descent, as a metaphor, starts to run out of road. Gradient descent assumes the objective is already given, stable, and worth optimizing. But research often begins one level earlier. Before we ask how to descend, we have to ask whether the current objective captures anything important at all. Once the problem becomes choosing, revising, or even inventing the objective itself, optimization alone is no longer enough. We need a language for acting under uncertainty while learning what is worth pursuing. That is the conceptual bridge to reinforcement learning.
Supervised learning, the paradigm most of us spend our days inside, is pure exploitation. Its entire belief system rests on a given loss function:
\[L_{\text{supervised}} = d(y_{\text{pred}}, y_{\text{true}}).\]There is an explicit $y_{\text{true}}$, a ground-truth coordinate we trust completely, and every experiment is an attempt to move infinitely closer to it.
Getting stuck, however, begins the moment you start questioning the value of that $y_{\text{true}}$ itself, or the relevance of the map as a whole. A different impulse surfaces: rather than perfecting your path through the illuminated terrain, you want to be the person who steps into the unknown and helps draw the map itself.
This is the turn from exploitation to exploration. It no longer asks how to minimize distance to a known point. It asks how to maximize cumulative future reward in an unknown world, through trial and error. This is the conceptual core of Reinforcement Learning (RL).
The objective shifts from a static $L$ to a dynamic expected return:
\[J(\pi) = \mathbb{E}\left[\sum_t \gamma^t r_t\right].\]To optimize $J$, we still introduce a surrogate loss $L_{\text{RL}}$ such as a policy-gradient objective or a TD error. But the meaning has changed entirely. You are no longer a passive consumer of the map. You have become its active author.
If we carry the RL metaphor one step further, the mapping becomes surprisingly tight. The agent is the researcher. The state space is the sprawling landscape of existing literature, open problems, and unexplained anomalies. The actions are the things we actually do: propose hypotheses, design experiments, reframe objectives, and test strange ideas. And the reward is not merely another tenth of a point on a benchmark, but an increase in what the field can explain, build, or newly see.
Now imagine the totality of human ignorance as an incomprehensibly vast terrain, most of it still uncharted. The scientific paradigms painstakingly constructed by previous generations represent the illuminated regions. Within those lit areas, it becomes possible to define a loss function $L$ that measures the mismatch between what our current theories say and what reality actually does. If you want a cleaner mathematical analogue, think of it as
\[L(\text{current theory}, \text{reality}),\]or, in a more machine-learning flavored form, $L(\text{our models}, \text{nature’s ground truth})$.
Every research project you labor over is, at its core, an attempt to reduce this $L$ by some small amount.
A “good idea,” then, is finding the direction on the current map where descent is most valuable: the steepest local gradient, $\nabla L$.
This framing maps with surprising precision onto Thomas Kuhn’s argument in The Structure of Scientific Revolutions. Kuhn observed that science does not advance along a smooth, continuous line. Instead, long stretches of “normal science” are punctuated by occasional, earth-shaking “paradigm shifts.”
These two states correspond precisely to the two mental models above. “Normal science” is quintessential exploitation: within the lit region, you perform gradient descent along the known loss function, methodically filling in every corner. A “paradigm shift” is radical exploration: driven by RL-style thinking, someone decides the lit region has been exhausted, or that the map itself is flawed, and pushes into the surrounding unknown to chart a new continent. The task is no longer to optimize an existing loss function, but to illuminate an entirely new region and define a new one, $L’$.

Understanding this distinction clarifies where you and your work currently sit. It explains why some people are making the existing light brighter, while others are busy lighting an entirely new lamp.
But before rushing downhill, a more pressing question demands an honest answer.
How do you know that the mountain you are on is worth climbing at all, rather than just a mound of unremarkable dirt?
When a field becomes intensely competitive and everyone is celebrating improvements to the third decimal place, it usually signals that the gradient across most of the illuminated region has flattened out. A first-rate thinker’s instinct is not to walk faster across flat ground, but to question the map itself and look toward the surrounding unknown with genuine curiosity.
The capacity to venture into the unknown is not some mystical form of inspiration. It has traceable sources. It might come from an act of cross-domain appropriation: seizing a concept from evolutionary biology or game theory and applying it to your own field, illuminating corners no one had thought to look in. It might also come from a more internal move, where you pick up a SOTA paper, treat it not as scripture but as a toy, modify its core assumptions, or drop it into an extreme environment it was never designed for, and listen carefully to what you learn as it fails.
Once you have internalized the habit of reading and redrawing the map, you can throw yourself into problem-solving with genuine confidence, knowing that every step you take is on solid and worthwhile ground.
Phase One: Mastering the Art of Problem-Solving in Normal Science
The vast majority of your research life will take place within the “normal science” era.
In this phase, the entire field shares a single paradigm. Everyone has implicitly agreed that the same loss function is worth optimizing. Under Newtonian mechanics, the shared loss was $L = \lvert \text{theoretically predicted planetary position} - \text{observed position} \rvert$. In modern AI, the dominant conceptual loss function is something like $L = 1 - \mathrm{Acc}$. Accuracy is not always the literal function being optimized in code, but it has become the de facto currency for ranking models and measuring progress. All the work everyone does is ultimately aimed at pushing this number down, even if only by a fraction of a percent.
Research during this era resembles solving a puzzle. The goal is not to discover a new continent, but to find a more elegant solution within the existing rules. Your core task is to become a master of gradient descent.
So how do you find the gradients worth following?
Technique one: actively probe the steepest terrain.
As a field matures, most gradients flatten. A serious researcher deliberately seeks out the corners that existing theory struggles most to explain, because those corners are where the gradient is still steep.
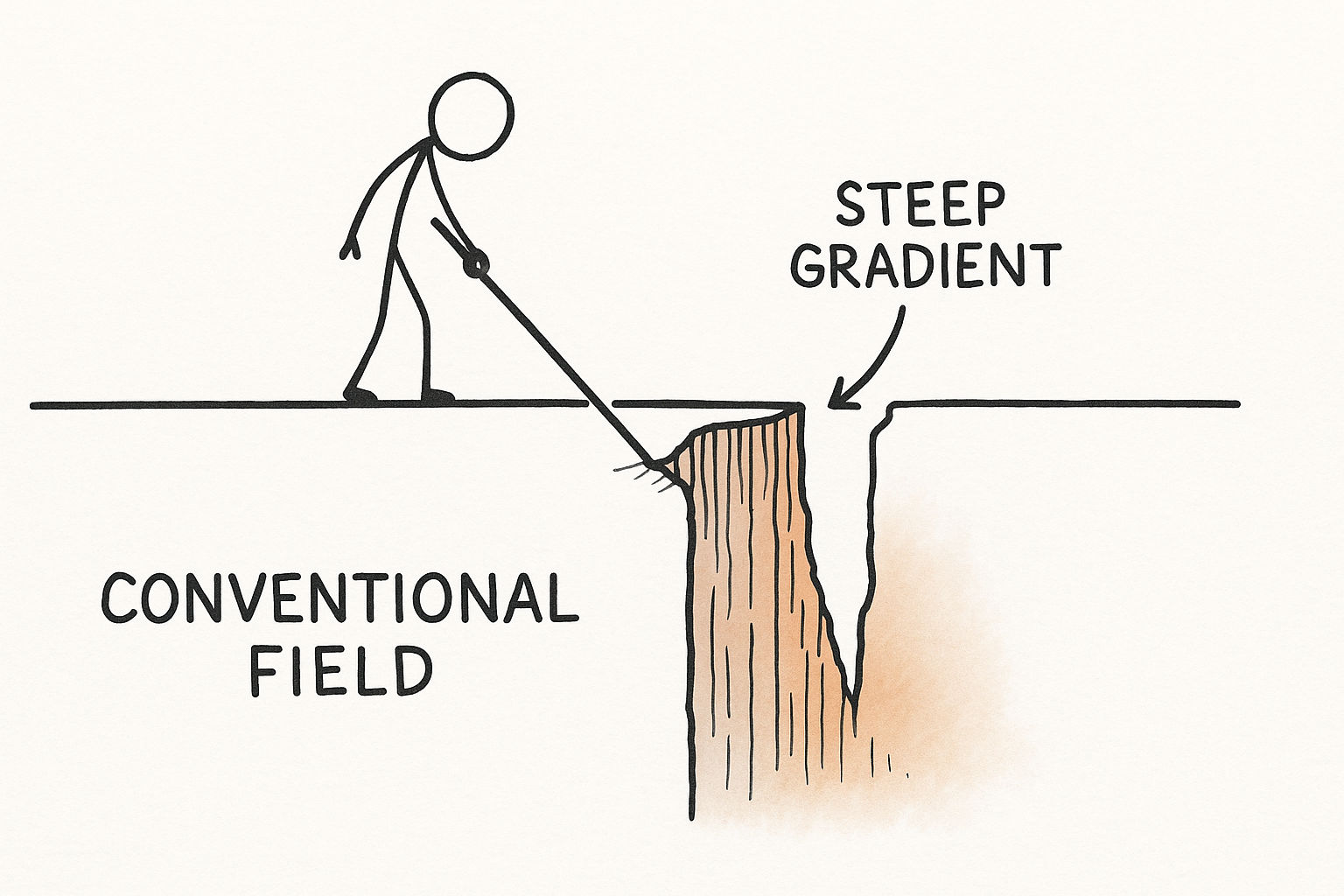
One approach is to probe the boundaries and target the hardest problems. Scientific revolutions have often begun exactly this way. In the late nineteenth century, the physics community largely believed Newtonian mechanics was nearly complete. In our terms, the loss $L$, representing the gap between theory and observation, was essentially zero for almost everything.
But at a few boundary cases, most famously the precession of Mercury’s perihelion, small but stubbornly persistent errors appeared. In those specific regions, $L$ was surprisingly high. Most researchers treated these as minor annoyances to be patched over. Einstein, however, recognized that these outliers were precisely where the existing theory was most exposed. Compared to the near-zero $L$ everywhere else, these boundary cases represented a steep, conspicuous gradient. Rather than applying a patch, he followed that gradient to its source and rebuilt physics from the ground up.
A second approach is to probe adversarial environments and excavate hidden vulnerabilities. Many SOTA models resemble hothouse flowers: impressive under controlled conditions, fragile when the environment turns hostile. Your task is to engineer the storm. Standard benchmarks paint too clean a picture. Design a “hell-mode” evaluation setting. Transform the loss from $L_{\text{task}}$ to $L_{\text{new}} = L_{\text{task}} \mid \text{adversarial conditions}$. When a model performs radically differently under these two regimes, you have found a legitimate direction in robustness research.
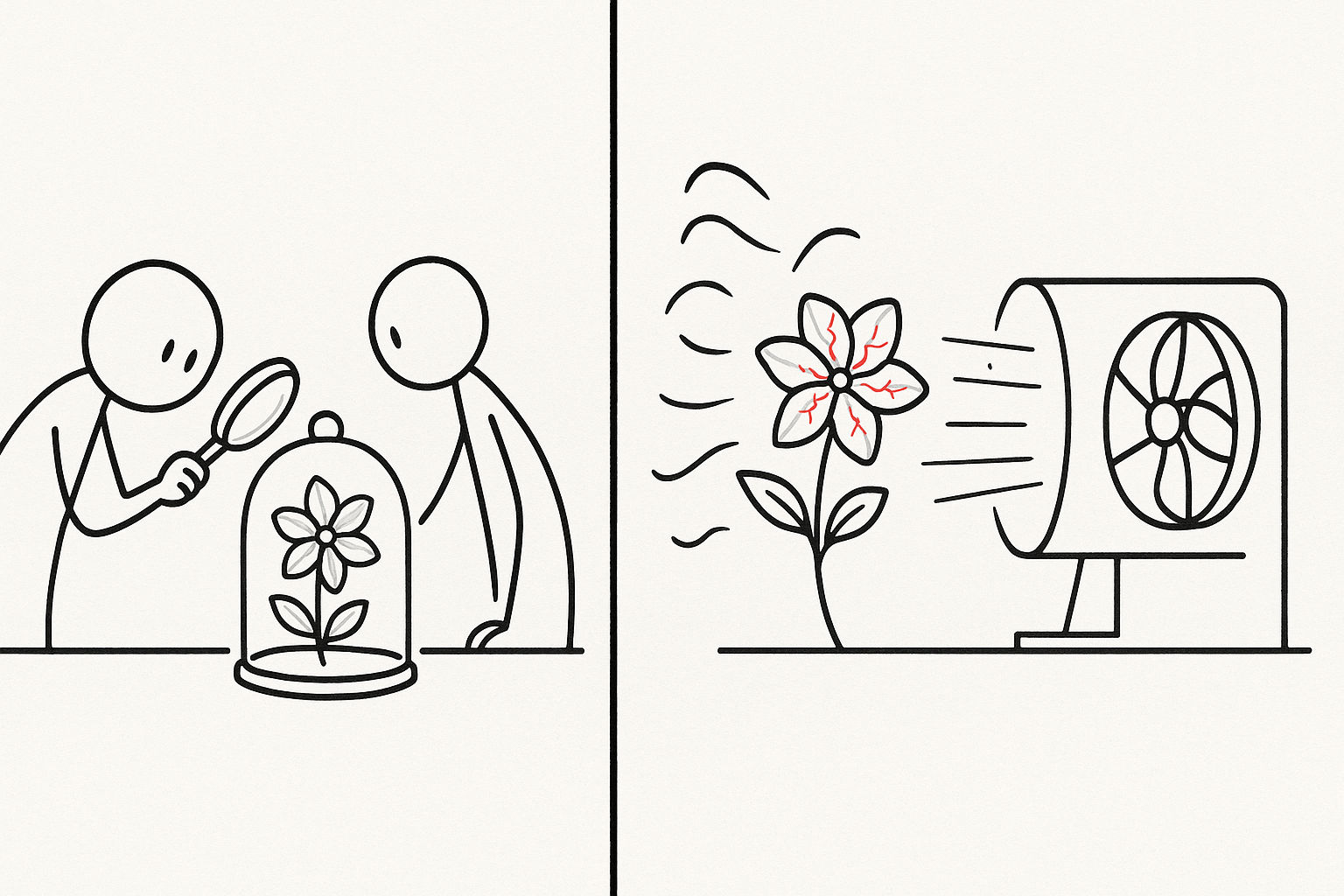
Technique two: manufacture the gradients that others have overlooked.
Sometimes the gradient is not absent; it is buried under assumptions so widely shared that no one thinks to question them.
One method is to lift the veil on hidden assumptions. Every theory rests on premises that go unexamined precisely because everyone accepts them. Consider one of the most consequential examples in recent AI history: the Transformer’s displacement of the RNN. The default assumption behind all sequence models was that language must be processed sequentially, token by token. This was not a conscious design choice; it was simply accepted as a fact about the domain. The attention mechanism in “Attention Is All You Need” overturned this assumption entirely. In optimization language, the field had been implicitly solving
\[\min_{\theta} L_{\text{LM}}(\theta) \quad \text{subject to sequential computation}.\]Vaswani and colleagues effectively relaxed that constraint and replaced it with a new one:
\[\min_{\theta} L_{\text{LM}}(\theta) \quad \text{subject to global attention and parallel computation}.\]What followed was not a marginal gain, but a categorical shift in what was possible. The real lesson here is not that attention is clever; it is that the assumption about sequential processing was a steep gradient that had been sitting under everyone’s feet, covered by a century of habit.
A similar move reshaped economics. Classical theory assumed perfect human rationality. In effect, it was optimizing under one model of human behavior; behavioral economics emerged when researchers replaced that assumption with a different one, closer to
\[\min_{\theta} L_{\text{task}}(\theta) \quad \text{subject to humans making systematic errors}.\]That single change opened a dense new landscape of gradients no one had previously considered.

Another method is to redefine what “good” means. Normal science carries a quiet danger: everyone becomes so focused on optimizing a score within a given game that they lose sight of what the game was meant to measure. Some of the most compelling ideas emerge from changing the ruler rather than the runner. Instead of $L = L_{\text{performance}}$, try
\[L_{\text{comprehensive}} = w_1 L_{\text{performance}} + w_2 L_{\text{efficiency}} + w_3 L_{\text{robustness}} + \cdots\]Measured against this new composite standard, yesterday’s champions may look surprisingly ordinary. Being the first to seriously optimize the new objective is equivalent to opening a new research subfield.
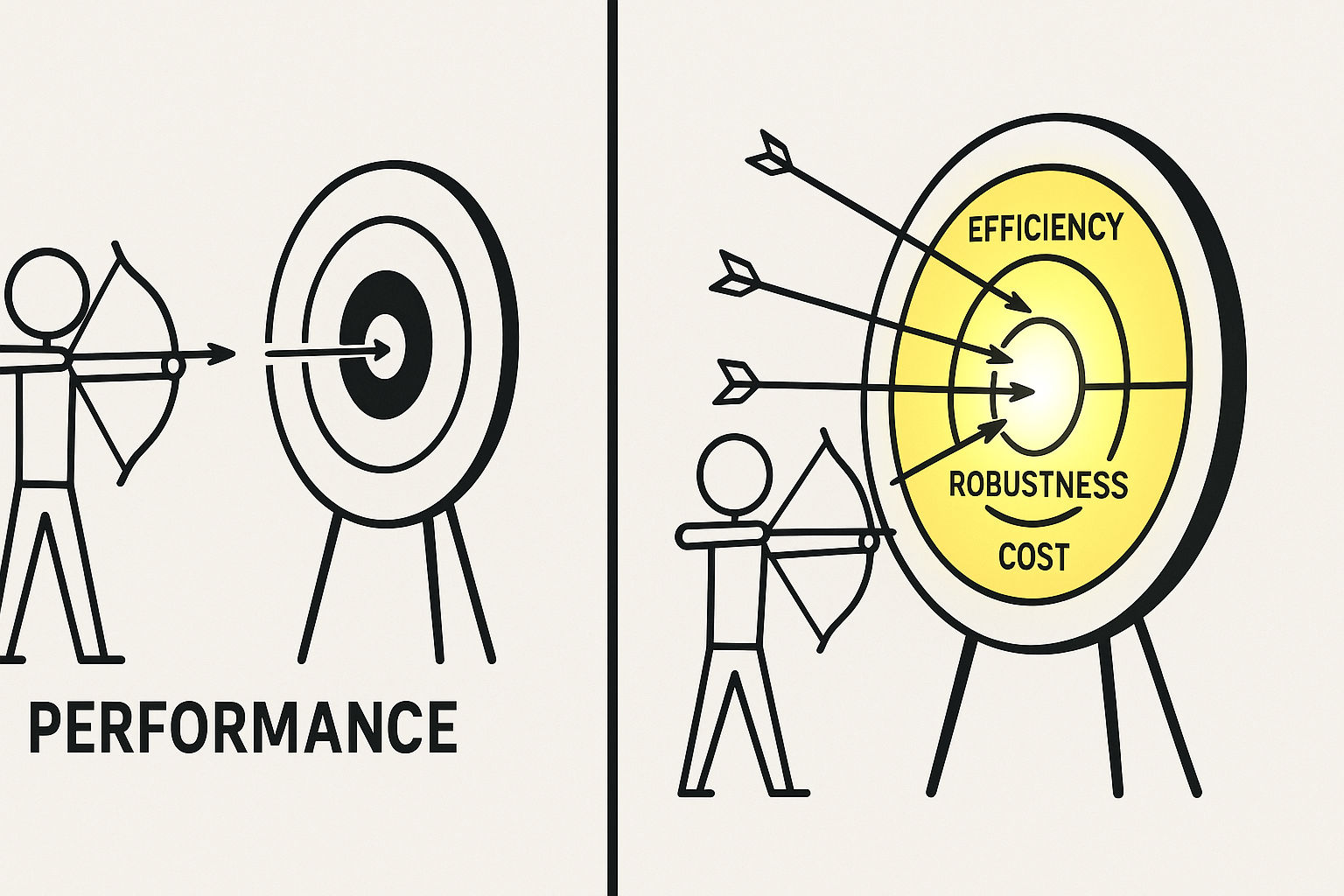
Technique three: find the most cost-effective descent path.
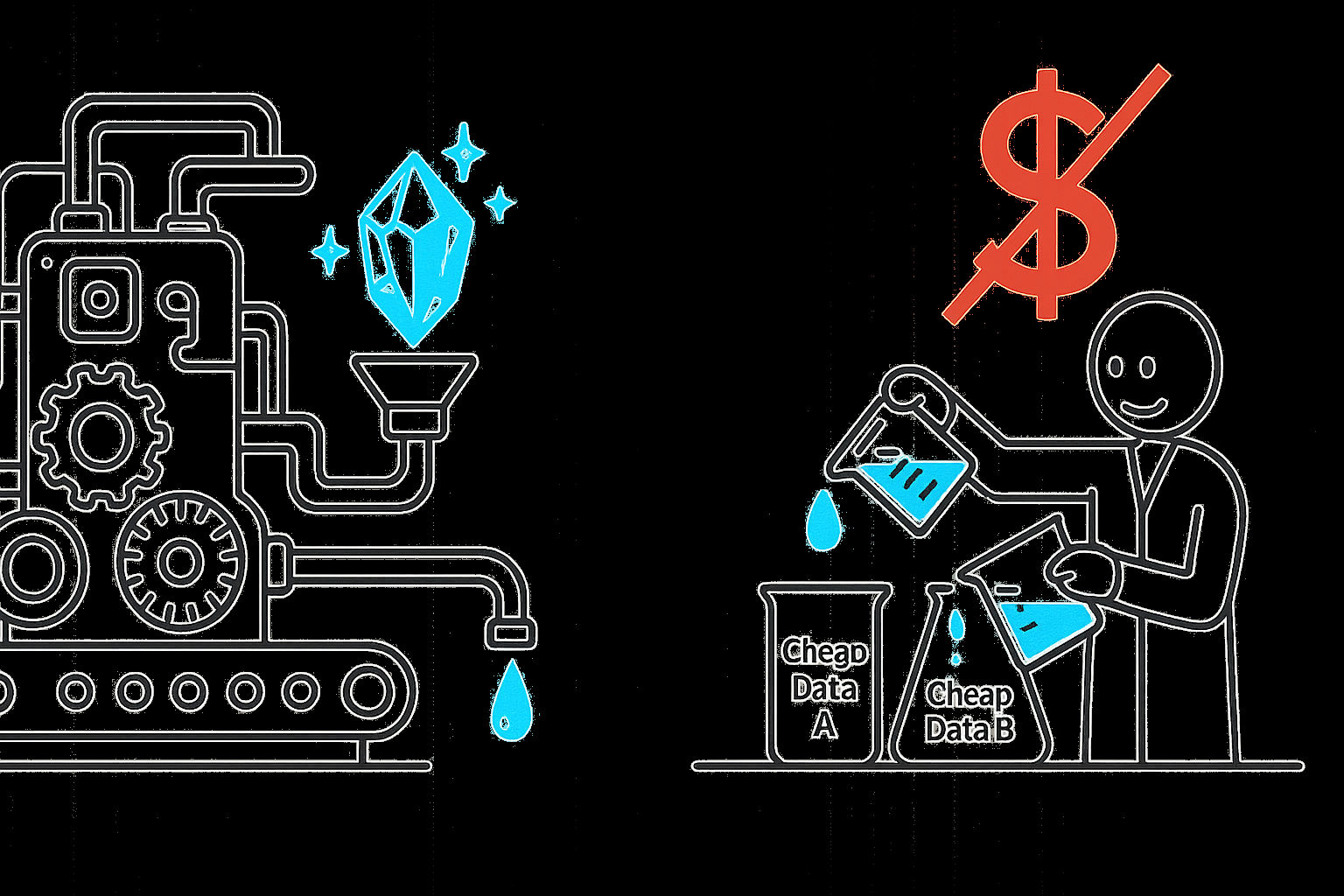
In practice, we all work under constraints. Cost is the most persistent one, and the pressure to do more with less has historically generated some of the most creative ideas.
You might optimize your data recipe. A SOTA model may require enormous quantities of expensive labeled data. Ask whether cheaper data could substitute. This reframes the problem as optimizing $L = L_{\text{performance}} + \lambda \cdot \mathrm{Cost}(\text{data})$, a constraint the original work likely never considered.
Alternatively, you might target a specific algorithmic module. A pipeline assembled years ago may be carrying outdated components. Replacing one of them with a more efficient modern alternative is equivalent to upgrading your optimizer: same destination, fraction of the cost.

Once you have internalized these techniques, you no longer need to wait anxiously for inspiration. Ideas can be worked out methodically, one step at a time.
Phase Two: Developing Academic Taste to Identify Ideas Worth Pursuing
Through the methods above, you may now have a list of seemingly viable ideas. But a new problem emerges. These ideas likely fall into two distinct categories: some invite you to descend more steeply within the existing illuminated terrain, while others invite you to explore a stretch of uncharted territory.
Faced with both options, how do you choose? This is the classic exploration-exploitation dilemma, and it appears in research just as it does in RL. Among the many ideas on your list, how do you judge which one is truly worth pursuing?
This question enters a domain that is more experience-dependent. We usually call it Taste.
Here is a more precise way to think about it. In reinforcement learning, an agent navigating a vast state space can act decisively because it carries an internal Value Function (or Q-value). This function does not evaluate the immediate reward of a single action; it estimates the long-term expected return of being in a given state, discounted across future time. Academic Taste is the research analogue of a Value Function. It is not intuition in the mystical sense. It is an evaluation model your mind has trained through years of reading, experimentation, and failure. When you stand before an unexplored idea, your Taste is performing a computation something like: what is the expected return of following this path, across all the effort it will eventually require?
The good news is that, like a Value Function, Taste can be decomposed into a set of learnable criteria.
And, crucially, it can be trained. In RL, a value function does not descend from heaven. It is updated through repeated interaction with the environment. Academic Taste works the same way. You read widely to observe the state space. You reproduce papers and run ablations to take actions. You pursue ideas that stall and collect negative reward. You notice which questions continue to generate signal, and which ones collapse on contact with reality. Over time, your internal estimate of what is worth doing becomes less romantic and more calibrated. Taste is not a gift. It is a learned research model.

Slope: how much potential does this idea carry?
How significant is the payoff? Is this a 0.1% lift on a mature leaderboard, or could it produce an order-of-magnitude improvement? More fundamentally: does this idea invite careful cultivation of a gently sloping but well-understood region, or does it point toward uncharted territory that might harbor a cliff-face of steep gradient? Researchers with well-developed Taste tend to feel instinctively indifferent toward small, safe gains. They are pulled toward ideas that might genuinely change the rules of the game.
Depth: are you treating a symptom or a cause?
Some ideas have steep apparent slopes but are shallow pits: once filled, the story ends. Ask yourself whether you are addressing a surface symptom or a load-bearing assumption. Treating symptoms means applying a stronger optimizer to the same $L$. Treating causes means interrogating whether $L$ itself is fundamentally mistaken, quietly pulling an entire field toward a false prosperity. Deep problems tend to point directly at the foundational assumptions of a field.
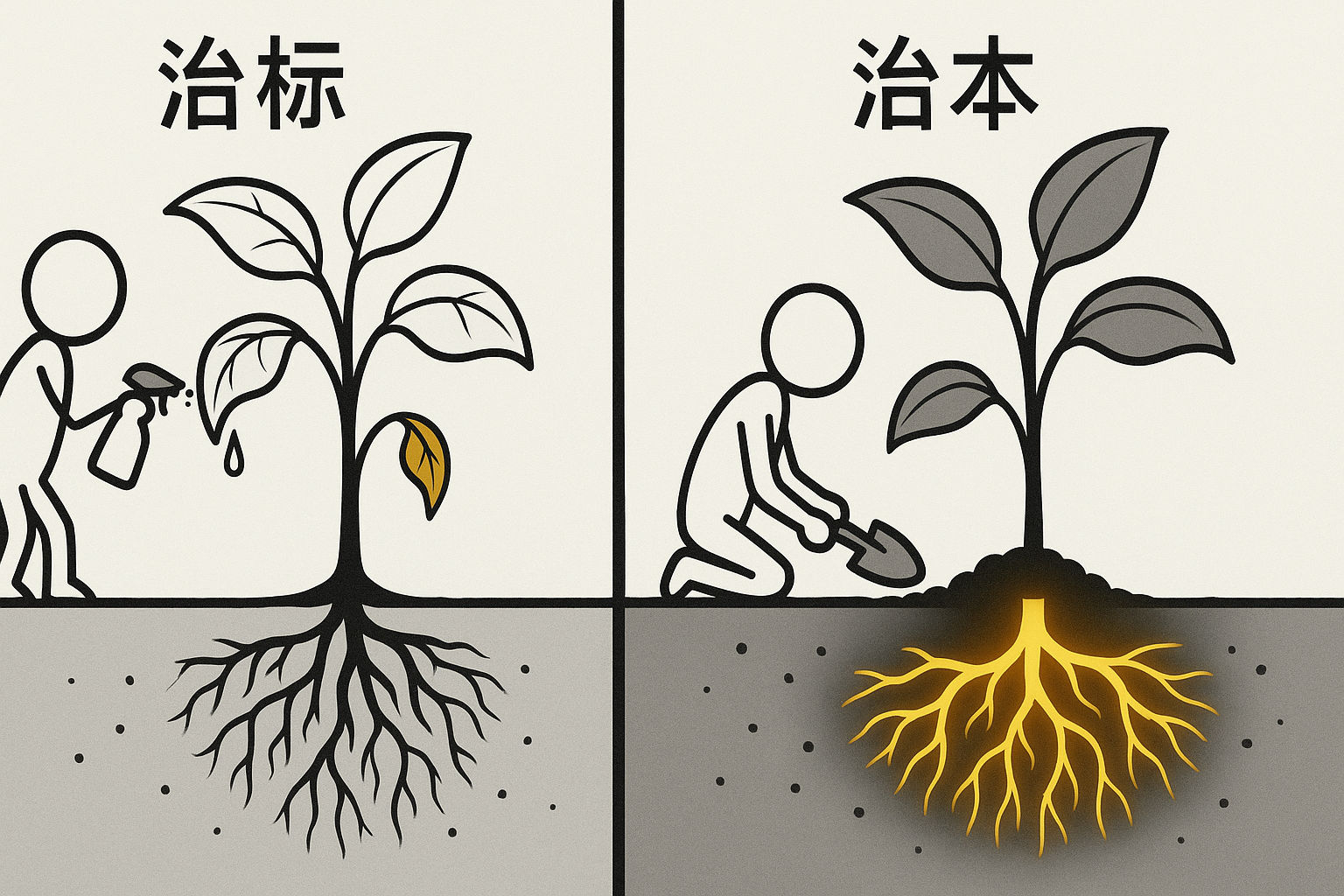
Extensibility: is this idea a door or a wall?
This measures generative potential. When you solve the problem, does it open onto a series of richer, more interesting questions, or does the story simply end? Researchers with strong Taste think like investors: they look for problems that compound. An extensible problem is like finding a door at the edge of the known map. Push it open, and behind it is a new region dense with unexplored gradients, a strong signal that an entire new continent is waiting.
Executability: can you actually reach it?
This is a reality check on all grand ambitions. Taste does not live in the clouds. Many incoming graduate students make the mistake of setting their sights immediately on questions like “how do we achieve AGI?” A mature Taste finds the ideal balance point between ambition and execution: choosing, within your actual capacity, the gradient that is simultaneously steepest, deepest, and most extensible.

Personal fit: does this problem genuinely excite you?
Research is a long, grinding marathon, typically marked by more failure than success. If a problem does not genuinely interest you at some deep level, you are unlikely to sustain the effort required to see it through. A strong personal fit provides the reserves to keep searching for a faint downhill direction when $\nabla L \approx 0$ and all obvious paths seem exhausted. What ultimately carries you through is something close to stubborn passion for the climb itself, independent of how slowly the summit approaches.

Phase Three: The RL Mindset, Designing the Reward Function
When you have practiced these techniques and sharpened your Taste, and when you are consistently producing work that matters, a deeper unease may surface some late night. You begin to feel less like someone solving problems and more like someone applying increasingly elaborate patches to a theory that is fundamentally cracking. A more fundamental question surfaces: what if the objective we are optimizing is exactly what is holding us back?
This is where paradigm shifts are born. What is needed now is a different mode of thinking entirely. Your attention moves away from the brightness of the light and toward the source of the light. In gradient-descent terms, you are no longer satisfied with finding the steepest $\nabla L$ on the existing map. In reinforcement-learning terms, you are no longer merely optimizing a policy inside a fixed environment. You are interrogating the reward function itself. You want to become the person who defines what counts as illuminated terrain in the first place. Your goal is to propose an entirely new worldview: a new loss function, $L’$, or equivalently, a new reward model for what the field should value.
This is the fully mature RL mindset in research. The revolutionary is not just exploring more aggressively. The revolutionary is redesigning what counts as reward.
This requires the courage to question standard pipelines. Mature fields develop canonical workflows, something like
\[L_{\text{standard}} = L(\text{model prediction}, \text{simulator ground truth}) + L(\text{policy reward within that model}).\]A genuinely restless thinker eventually asks: why are we fitting a simulator that is, by definition, a fabrication of reality?
More fundamentally, it requires the willingness to reason from first principles. A true paradigm shift almost always arrives through a redefinition of the field’s most fundamental loss function. When Einstein encountered persistent errors that $L_{\text{Newtonian}}$ could not account for, he did not search for a better optimizer for $L_{\text{Newtonian}}$. He threw away the old map entirely and defined a new reality, effectively establishing a new baseline where the “loss” was governed by the geometry of spacetime itself:
\[\mathrm{Eq}_{\mathrm{GR}}(g, T) = 0.\]That was not a more elegant descent. That was a revolution in what it means to descend.
Our era has its own version of this story, and it is worth examining closely. AlexNet’s breakthrough in 2012 did not merely improve scores on a benchmark. It revealed a gradient so steep it made the entire field stop breathing. Its implicit objective, $L_{\text{AlexNet}} = 1 - \mathrm{Acc}_{\text{ImageNet}}$, was written into history, and the field flooded in to minimize it.
But the more important story is what came next. Before ChatGPT, every language model in the industry was grinding the same loss function: next-token prediction, cross-entropy over a vast corpus. The entire field was converging toward a local optimum, and most practitioners did not realize they were stuck. Then OpenAI introduced RLHF, Reinforcement Learning from Human Feedback. In doing so, they effectively told the world: stop fitting the corpus. The new objective is something closer to optimizing for human usefulness and alignment rather than pure next-token likelihood. Here, RL is not just the algorithm they used; it perfectly embodies the conceptual shift in their research approach. They were not merely optimizing better. They were redefining the reward model.
This was not a more efficient path to the same destination. It was a different destination entirely. The wave of development that followed, spanning hundreds of competing models and reorienting the priorities of an entire industry, is what a paradigm shift looks like from the inside. The old map was not improved. It was replaced.
Now, frontier researchers are asking the next version of the question: what should the loss function of a genuinely intelligent learning system actually be? A candidate taking shape at the frontier of the field looks something like
\[L_{\text{new}} = w_1 (1 - \mathrm{Accuracy}) + w_2 (\mathrm{EnergyCost}) + w_3 (\mathrm{SampleEfficiency}) + \cdots\]Whoever finds an effective descent path on this new surface first may well open the next era.
Closing
A good research idea is not a bolt of inspiration. It is a trainable pattern of perception: the ability to read through the surface of the literature and see an underlying map of information gradients, dense with opportunity that others have not yet noticed.
Science has always produced two equally great kinds of scientists.
The first is the normal scientist: someone who gives better answers to existing questions. Using the sharpest methods available, they push a paradigm toward its full potential, making irreplaceable contributions to a field’s depth and richness. The logic of gradient descent runs through everything they do.
The second is the revolutionary: someone who poses an entirely new, more valuable question. They are willing to challenge what everyone else has simply accepted, to define a fundamentally new loss function, and in doing so, to open a new era. The spirit of RL-style exploration burns at the core of everything they attempt.
Both roles are indispensable, and neither is subordinate to the other. In a healthy research ecosystem, they are symbiotic. Exploration without disciplined optimization dissipates into vague ambition. Optimization without exploratory courage collapses into sterile incrementalism. Great research often requires both moves in sequence: first the RL mindset to find or redefine the problem, then the GD mindset to solve it with rigor.
So, having read this far, it is worth sitting with a question of your own: do you find more satisfaction in pushing an existing paradigm toward its limits as a solver, or does your pulse quicken at the thought of lighting the next revolution as a question-setter?
Whatever your answer, both pursuits call for the same two tools: the disciplined depth of gradient descent thinking, and the restless, generative breadth of reinforcement learning thinking. They are not opposites. They are complementary. One hand searches for the right objective. The other hand does the hard work of optimizing it. Serious science needs both. The best researchers know when to think in reinforcement learning, and when to descend with gradient descent.
The map you inherit determines your starting point. The map you choose to draw will determine your legacy.